Home
🛡️ Pegasi - Safety toolkit to make LLMs reliable and safe
Pegasi Shield is our community edition developer toolkit to use LLMs safely and securely. Our Shield provides generic safeguards prompts and LLM interactions from costly risks to bring your AI app from prototype to production faster with confidence.
Our Pegasi team can work with you to customize Shield into your enterprise LLM applications, build workflow-specific detectors and autocorrectors for your business use cases, and integrate with your favorite monitoring / SIEM tools.
What does Shield do?
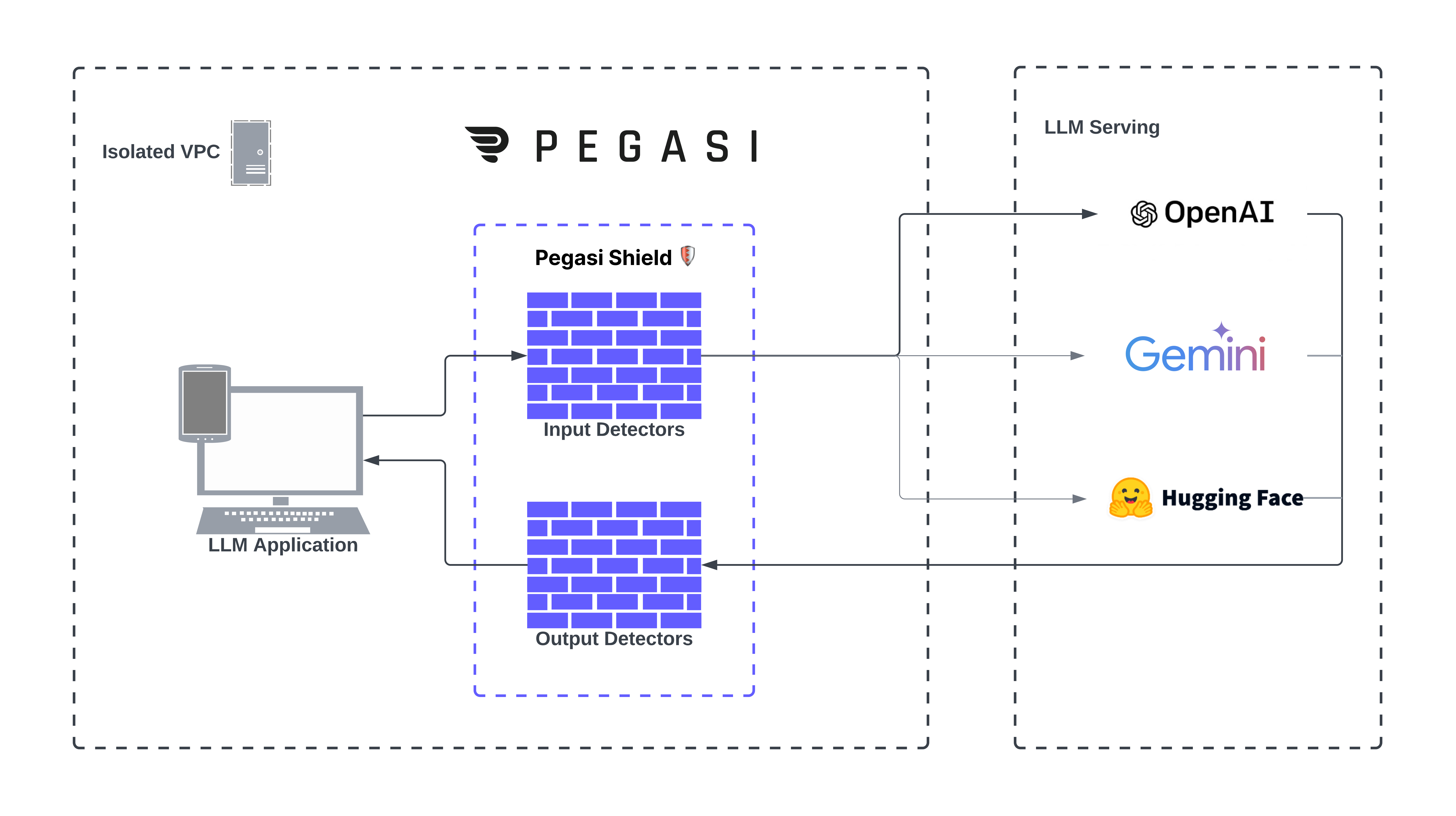
Our Shield wraps your GenAI apps with a protective layer, safeguarding malicious inputs and filtering model outputs. Our comprehensive toolkit has 20+ out-of-the-box detectors for robust protection of your GenAI apps in workflow.
From prompt injections, PII leakage, DoS to ungrounded additions (hallucinations) and harmful language detection, our shield protects LLMs through a multi-layered defense. Lastly, we can work with you to create custom detectors.
Installation
$ PEGASI_API_KEY="******"
$ pip install pegasi-shield
Contact our team to get an API key and partner together to unlock value faster.
Usage
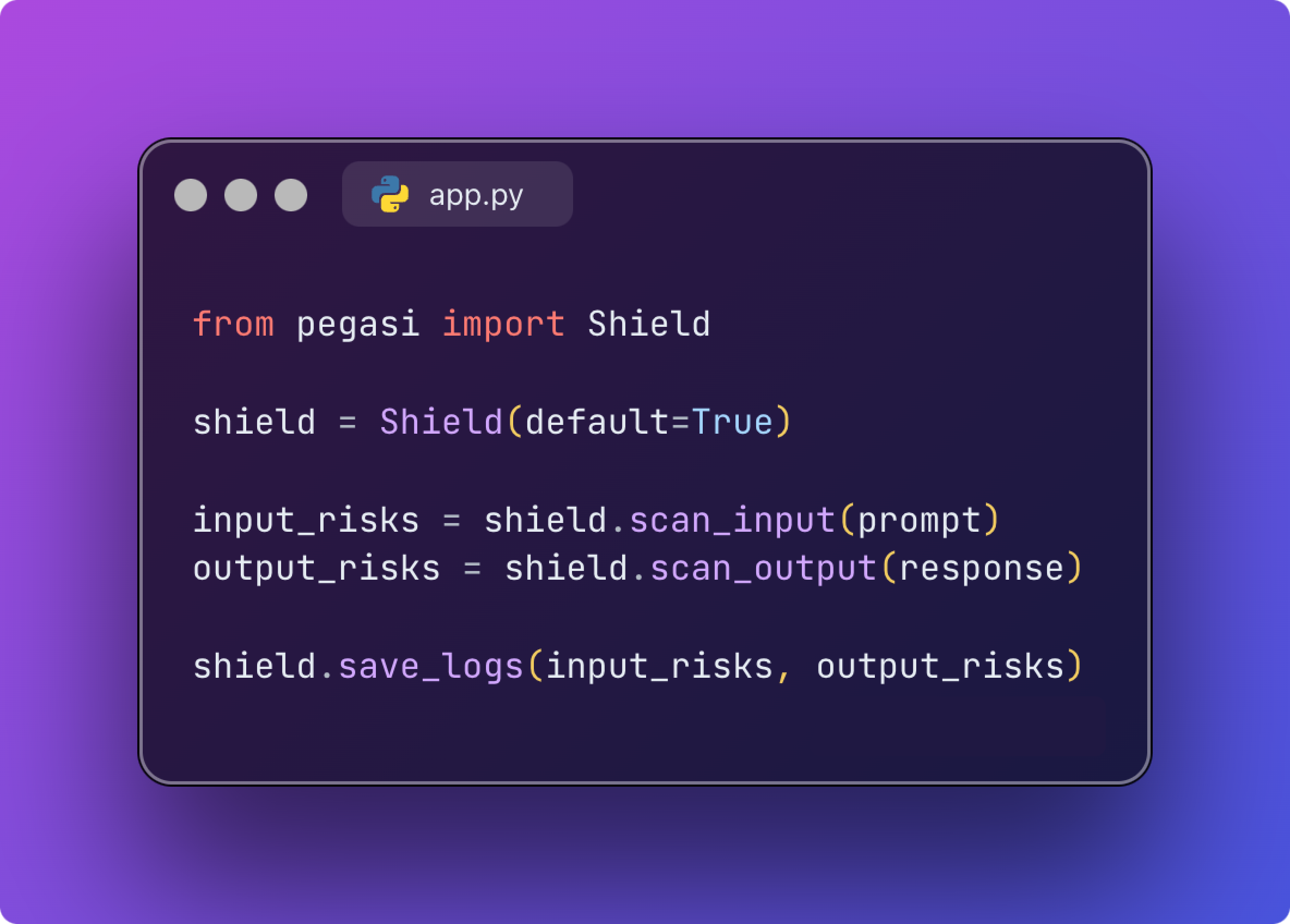
We have both an API that can be deployed as a Docker container in your VPC or our customizable Python SDK.
Book a demo with the Pegasi team to learn more.
Features
Pegasi is a Compound AI System where it orchestrates different components to work as a cohesive unit, where each component has their specializations and can collaborate towards a common safety objective.
Our default Shield covers most of the Detectors, except for the Auto-correctors for repairing LLM outputs which is for teams who are scaling. We will work with you to fine-tune our detectors and build custom detectors for your unique workflow.
- Input Safety Detectors
- Anonymize
- Bias
- DoS Tokens
- Malware URL
- Prompt Injections
- Secrets
- Stop Input Substrings
- Toxicity
- Harmful Moderation
- Coding Language *
coding languagerequired - Regex *
patternsrequired
- Output Safety Detectors
- Bias
- Deanonymize
- Sensitive PII
- Stop Output Substrings
- Toxicity *
perspective_api_keyrequired - Harmful Moderation
- Regex *
patternsrequired - Coding Language *
coding languagerequired - Relevance
- Groundedness
- Factual Consistency
- Contradictions
- Query-Context Relevance
- Output-Context Relevance
- Query-Output Relevance
- Text Quality
Multi-layered defense
- Deep Learning Detectors (Community Edition): detect and filter potentially harmful input before reaching LLMs
- LLM-based detectors (Professional/Enterprise): use our fine-tuned safety LLM to analyze inputs and outputs to identify potential safety and security risks
- Vector Database (Professional/Enterprise): store previous risks in a vector database to recognize and prevent similar risks
- Autocorrect (Professional/Enterprise): catch and correct AI errors in real-time with reasoning, confidence, and evidences.
Customize
There is no one-size-fits-all guardrail detection to prevent all risks. This is why we encourage users to reach out and partner with us to fine-tune and customize our Shield to cover safety areas relevant to your unique use cases.